迭代DFS是怎么回溯的?
How does iterative DFS traverse back?
以下程序找到总和为给定数字的路径。
def hasPathSum(self, root, sum):
if root is None:
return False
stack = [(root, sum)]
while stack:
node, _sum = stack.pop()
if node.left is node.right is None and node.val == _sum:
return True
if node.left:
stack.append((node.left, _sum - node.val))
if node.right:
stack.append((node.right, _sum - node.val))
return False
它使用带有堆栈的迭代 DFS。我了解程序的大部分内容,但我不知道如果到达叶节点,它是如何遍历回来的。
我想回溯的唯一方法是为每个节点调用函数。这就是我们称之为迭代的原因。我的理解正确完整吗?或者更准确地说,我们不回溯。我们只是从一个新的子节点开始。
如果这是真的,那么我们重新访问许多路径是在浪费时间,不是吗?
Here您可以看到迭代加深搜索如何工作的图像。
它以与深度优先搜索相同的顺序访问搜索树中的节点,但首先访问节点的累积顺序实际上是广度优先。
它returns到根节点并增加搜索的深度。
在上面的程序中我认为总和值定义了算法从根开始搜索的距离node.So我想向后遍历你应该再次调用该函数根值相同,和值增加。
我认为通过查看算法执行时堆栈上的哪些节点可以更容易地了解这里发生了什么。例如,假设我们有这棵树:
A
/ \
B C
/ \
D E
我们从包含 A 的堆栈开始:
A
/ \
B C Stack: A
/ \
D E
我们将 A 弹出堆栈并压入 B 和 C:
A
/ \
B C Stack: B, C
/ \
D E
现在,我们将 C 弹出堆栈并将 D 和 E 压入:
A
/ \
B C Stack: B, D, E
/ \
D E
现在,我们将 E 弹出堆栈。此时,我们处于一片叶子上,所以我们不再向树中添加任何东西。
A
/ \
B C Stack: B, D
/ \
D E
你问我们 "back up" 在这一点上如何。这里没有任何明确的内容可以让我们 "back up," 而是我们只是将下一个节点从堆栈中弹出并继续在那里寻找。下一个节点是 D,因此我们已经通过 C 进行了有效备份,现在正在尝试节点 D。
由于D也没有children,我们直接从栈中弹出:
A
/ \
B C Stack: B
/ \
D E
栈顶现在是B,所以我们已经隐式"backed up"到A,然后探索下一个A的children,B。B没有children,所以我们将它从堆栈中弹出,探索终止。
希望这能让您了解备份是如何发生的——当许多节点被推入堆栈时,只有其中一个被探索,其余的被推迟到以后。然后通过 "jumping back" 隐式实现备份到另一个较早发现但未访问过的节点。
您在此处拥有的特定 DFS 代码会在每个级别进行一些额外处理以跟踪剩余金额,我将把它作为练习留给 Reader 以了解其工作原理。
与此同时,请注意,使用此类图片跟踪代码通常是了解一段代码实际作用的最佳方式。单独阅读代码并查看其效果非常困难,但通过绘制正确的图片,其执行和行为可以变得更加清晰。
以下程序找到总和为给定数字的路径。
def hasPathSum(self, root, sum):
if root is None:
return False
stack = [(root, sum)]
while stack:
node, _sum = stack.pop()
if node.left is node.right is None and node.val == _sum:
return True
if node.left:
stack.append((node.left, _sum - node.val))
if node.right:
stack.append((node.right, _sum - node.val))
return False
它使用带有堆栈的迭代 DFS。我了解程序的大部分内容,但我不知道如果到达叶节点,它是如何遍历回来的。
我想回溯的唯一方法是为每个节点调用函数。这就是我们称之为迭代的原因。我的理解正确完整吗?或者更准确地说,我们不回溯。我们只是从一个新的子节点开始。
如果这是真的,那么我们重新访问许多路径是在浪费时间,不是吗?
Here您可以看到迭代加深搜索如何工作的图像。
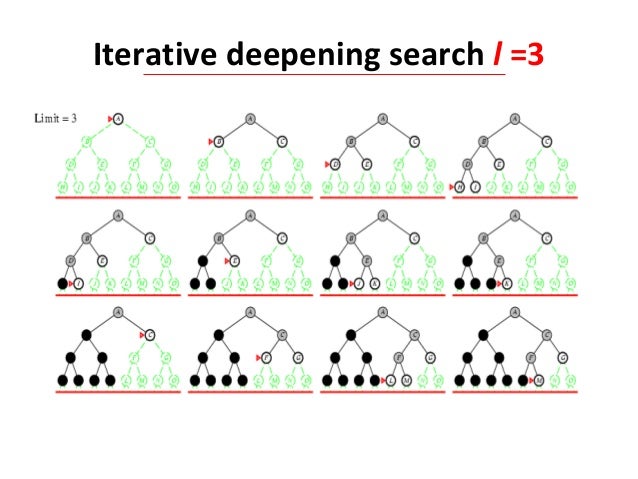{kind=link}
它以与深度优先搜索相同的顺序访问搜索树中的节点,但首先访问节点的累积顺序实际上是广度优先。
它returns到根节点并增加搜索的深度。
在上面的程序中我认为总和值定义了算法从根开始搜索的距离node.So我想向后遍历你应该再次调用该函数根值相同,和值增加。
我认为通过查看算法执行时堆栈上的哪些节点可以更容易地了解这里发生了什么。例如,假设我们有这棵树:
A
/ \
B C
/ \
D E
我们从包含 A 的堆栈开始:
A
/ \
B C Stack: A
/ \
D E
我们将 A 弹出堆栈并压入 B 和 C:
A
/ \
B C Stack: B, C
/ \
D E
现在,我们将 C 弹出堆栈并将 D 和 E 压入:
A
/ \
B C Stack: B, D, E
/ \
D E
现在,我们将 E 弹出堆栈。此时,我们处于一片叶子上,所以我们不再向树中添加任何东西。
A
/ \
B C Stack: B, D
/ \
D E
你问我们 "back up" 在这一点上如何。这里没有任何明确的内容可以让我们 "back up," 而是我们只是将下一个节点从堆栈中弹出并继续在那里寻找。下一个节点是 D,因此我们已经通过 C 进行了有效备份,现在正在尝试节点 D。
由于D也没有children,我们直接从栈中弹出:
A
/ \
B C Stack: B
/ \
D E
栈顶现在是B,所以我们已经隐式"backed up"到A,然后探索下一个A的children,B。B没有children,所以我们将它从堆栈中弹出,探索终止。
希望这能让您了解备份是如何发生的——当许多节点被推入堆栈时,只有其中一个被探索,其余的被推迟到以后。然后通过 "jumping back" 隐式实现备份到另一个较早发现但未访问过的节点。
您在此处拥有的特定 DFS 代码会在每个级别进行一些额外处理以跟踪剩余金额,我将把它作为练习留给 Reader 以了解其工作原理。
与此同时,请注意,使用此类图片跟踪代码通常是了解一段代码实际作用的最佳方式。单独阅读代码并查看其效果非常困难,但通过绘制正确的图片,其执行和行为可以变得更加清晰。