epsilon 贪婪 q 学习中的 Epsilon 和学习率衰减
Epsilon and learning rate decay in epsilon greedy q learning
我知道 epsilon 标志着探索和开发之间的权衡。一开始,您希望 epsilon 很高,这样您就可以大跃进并学到东西。当您了解未来的奖励时,epsilon 应该衰减,以便您可以利用您发现的更高 Q 值。
但是,在随机环境中,我们的学习率是否也会随着时间衰减?我看到的关于 SO 的帖子只讨论了 epsilon 衰减。
我们如何设置 epsilon 和 alpha 以使值收敛?
At the beginning, you want epsilon to be high so that you take big leaps and learn things
我认为你弄错了 epsilon 和学习率。这个定义其实跟学习率有关
学习率衰减
学习率是您在寻找最优策略时的飞跃幅度。在简单的 QLearning 方面,它是每一步更新 Q 值的程度。
更高的 alpha 意味着您正在大步更新您的 Q 值。当代理正在学习时,您应该衰减它以稳定您的模型输出,最终收敛到最佳策略。
Epsilon 衰减
当我们根据已有的 Q 值select执行特定操作时,将使用 Epsilon。例如,如果我们 select 纯贪心法 ( epsilon = 0 ),那么我们总是 select 特定状态的所有 q 值中的最高 q 值。这会导致探索出现问题,因为我们很容易陷入局部最优。
因此我们使用 epsilon 引入随机性。例如,如果 epsilon = 0.3,那么无论实际 q 值如何,我们都会 select 以 0.3 的概率进行随机操作。
查找有关 epsilon-greedy 策略的更多详细信息 here。
总而言之,学习率与你的跳跃幅度有关,而 epsilon 与你采取行动的随机性有关。随着学习的进行,两者都应该衰减以稳定和利用收敛到最佳策略的学习策略。
作为 Vishma Dias 的答案描述的学习率 [衰减],我想详细说明我认为这个问题隐含提到的 epsilon-greedy 方法 decayed-epsilon-greedy探索和开发的方法。
在训练 RL 策略期间平衡探索和利用的一种方法是使用 epsilon-greedy 方法。例如, =0.3 表示输出动作是从动作 space 中随机选择的概率 =0.3,而输出动作是基于 argmax(Q) 贪婪选择的输出动作。
=0.3 表示输出动作是从动作 space 中随机选择的概率 =0.3,而输出动作是基于 argmax(Q) 贪婪选择的输出动作。
改进的 epsilon-greedy 方法称为 decayed-epsilon-greedy 方法。
在这种方法中,例如,我们训练一个总共有 Nepochs/episodes 的策略(这取决于具体问题),算法初始设置 =(例如,=0.6),然后在 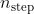 训练 epoches/episodes 期间逐渐减少到 =
训练 epoches/episodes 期间逐渐减少到 =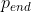 (例如,=0.1)结束。
具体来说,在初始训练过程中,我们让模型更自由地以高概率探索(例如,
(例如,=0.1)结束。
具体来说,在初始训练过程中,我们让模型更自由地以高概率探索(例如,=0.6),然后以 的速率逐渐减少 r over training epochs/episodes 使用以下公式:
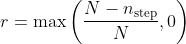
有了这种以非常小的探索概率 结束的更灵活的选择,在 之后,训练过程将更多地关注开发(即贪婪),同时它仍然可以探索当策略近似收敛时概率非常小。
您可以在 this post 中看到 decayed-epsilon-greedy 方法的优势。
我知道 epsilon 标志着探索和开发之间的权衡。一开始,您希望 epsilon 很高,这样您就可以大跃进并学到东西。当您了解未来的奖励时,epsilon 应该衰减,以便您可以利用您发现的更高 Q 值。
但是,在随机环境中,我们的学习率是否也会随着时间衰减?我看到的关于 SO 的帖子只讨论了 epsilon 衰减。
我们如何设置 epsilon 和 alpha 以使值收敛?
At the beginning, you want epsilon to be high so that you take big leaps and learn things
我认为你弄错了 epsilon 和学习率。这个定义其实跟学习率有关
学习率衰减
学习率是您在寻找最优策略时的飞跃幅度。在简单的 QLearning 方面,它是每一步更新 Q 值的程度。
更高的 alpha 意味着您正在大步更新您的 Q 值。当代理正在学习时,您应该衰减它以稳定您的模型输出,最终收敛到最佳策略。
Epsilon 衰减
当我们根据已有的 Q 值select执行特定操作时,将使用 Epsilon。例如,如果我们 select 纯贪心法 ( epsilon = 0 ),那么我们总是 select 特定状态的所有 q 值中的最高 q 值。这会导致探索出现问题,因为我们很容易陷入局部最优。
因此我们使用 epsilon 引入随机性。例如,如果 epsilon = 0.3,那么无论实际 q 值如何,我们都会 select 以 0.3 的概率进行随机操作。
查找有关 epsilon-greedy 策略的更多详细信息 here。
总而言之,学习率与你的跳跃幅度有关,而 epsilon 与你采取行动的随机性有关。随着学习的进行,两者都应该衰减以稳定和利用收敛到最佳策略的学习策略。
作为 Vishma Dias 的答案描述的学习率 [衰减],我想详细说明我认为这个问题隐含提到的 epsilon-greedy 方法 decayed-epsilon-greedy探索和开发的方法。
在训练 RL 策略期间平衡探索和利用的一种方法是使用 epsilon-greedy 方法。例如,=0.3 表示输出动作是从动作 space 中随机选择的概率 =0.3,而输出动作是基于 argmax(Q) 贪婪选择的输出动作。
改进的 epsilon-greedy 方法称为 decayed-epsilon-greedy 方法。
在这种方法中,例如,我们训练一个总共有 Nepochs/episodes 的策略(这取决于具体问题),算法初始设置 =
训练 epoches/episodes 期间逐渐减少到
=
(例如,
=0.1)结束。
具体来说,在初始训练过程中,我们让模型更自由地以高概率探索(例如,
r over training epochs/episodes 使用以下公式:
有了这种以非常小的探索概率 结束的更灵活的选择,在
之后,训练过程将更多地关注开发(即贪婪),同时它仍然可以探索当策略近似收敛时概率非常小。
您可以在 this post 中看到 decayed-epsilon-greedy 方法的优势。