从 PuLP 到 GEKKO:约束的语法映射,Objective 函数
From PuLP to GEKKO: Syntax Mapping for Constraints, Objective Function
我正在研究最初在 PuLP 中建模的 人员分配问题 。然而,在开发过程中,一些约束以及 objective 变得非线性。比较了一些包后,我选择了GEKKO,但不知为何我的优化上不去,运行.
我面临两个问题:
1.约束公式
假设我有简单的约束,例如 these。
在 PuLP 我有类似的东西:
# Each position p must be assigned to exactly one employee e
for p in position_names:
succession_prob += pulp.lpSum([X[p][e] for e in employee_names]) == 1
# Only employees e that are qualified for position p can be selected
for p in position_names:
for e in employee_names:
succession_prob += X[p][e] <= position_mapping[p][e]
我在 GEKKO 中尝试做这样的事情:
# Each position p must be assigned to exactly one employee e
for p in range(len(position_names)):
m.Equation(sum(X[p][e] for e in range(len(employee_names))) == 1)
# Only employees e that are qualified for position p can be selected
for p in range(len(position_names)):
for e in range(len(employee_names)):
m.Equation(X[p][e] <= position_mapping.iloc[e][p])
这并没有给我一个错误,但我不确定它是否正确。但是,当我尝试拆分(相当复杂的)objective 函数时出现错误:
2。分割objective函数
# Dummy functions
numerator = pulp.lpSum(some expression)
denominator = pulp.lpSum(some other expression)
succession_prob += numerator / denominator
我再次尝试在 GEKKO 中做这样的事情:
numerator = m.Param(some expression)
denominator = m.Param(some other expression)
# Objective function: RCD moves -> max
m.Obj((numerator / denominator)*(-1))
>>> ERROR: unsupported operand type(s) for *: 'float' and 'generator'
我想知道我的约束代码是否正确(变量类型的选择等),以及如何修复拆分 objective。我很感激任何帮助,因为我已经尝试了不同的变量,但就是不行 运行.
对于#1,您的约束公式看起来是正确的。您可以通过使用 m.open_folder() 打开 运行 文件夹并使用文本编辑器打开 .apm 文件来检查 Gekko 写的内容。它列出了所有方程式、参数、变量和 objective 语句。
对于#2,除了您包含的内容外,您可能还有其他错误。此外,参数值是固定的 - objective 函数通常具有由优化器调整的变量类型。否则,如果 objective 函数仅包含参数值,那么它是一个不会影响解决方案的常数,除非从 objective.
中添加或减去一个常数
下面是一个简单的程序,您可以使用它来研究 Gekko 如何编写模型 .apm 文件。
from gekko import GEKKO
import pandas as pd
m = GEKKO()
print(m._path)
x = m.Array(m.Var,(3,4))
mydict = [{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000 }]
w = pd.DataFrame(mydict)
y = [0,2]
z = [1,3]
for p in range(len(y)):
m.Equation(sum(x[p][e] for e in range(len(z)))==1)
for p in range(len(y)):
for e in range(len(z)):
m.Equation(x[p][e] < w.iloc[e][p])
for p in range(np.size(x,0)):
for e in range(np.size(x,1)):
m.Obj(x[p][e]**2)
m.solve(disp=True)
print(x)
m.open_folder()
我正在研究最初在 PuLP 中建模的 人员分配问题 。然而,在开发过程中,一些约束以及 objective 变得非线性。比较了一些包后,我选择了GEKKO,但不知为何我的优化上不去,运行.
我面临两个问题:
1.约束公式
假设我有简单的约束,例如 these。
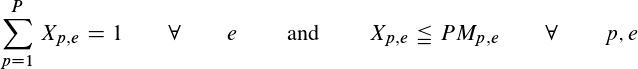{kind=link}
在 PuLP 我有类似的东西:
# Each position p must be assigned to exactly one employee e
for p in position_names:
succession_prob += pulp.lpSum([X[p][e] for e in employee_names]) == 1
# Only employees e that are qualified for position p can be selected
for p in position_names:
for e in employee_names:
succession_prob += X[p][e] <= position_mapping[p][e]
我在 GEKKO 中尝试做这样的事情:
# Each position p must be assigned to exactly one employee e
for p in range(len(position_names)):
m.Equation(sum(X[p][e] for e in range(len(employee_names))) == 1)
# Only employees e that are qualified for position p can be selected
for p in range(len(position_names)):
for e in range(len(employee_names)):
m.Equation(X[p][e] <= position_mapping.iloc[e][p])
这并没有给我一个错误,但我不确定它是否正确。但是,当我尝试拆分(相当复杂的)objective 函数时出现错误:
2。分割objective函数
# Dummy functions
numerator = pulp.lpSum(some expression)
denominator = pulp.lpSum(some other expression)
succession_prob += numerator / denominator
我再次尝试在 GEKKO 中做这样的事情:
numerator = m.Param(some expression)
denominator = m.Param(some other expression)
# Objective function: RCD moves -> max
m.Obj((numerator / denominator)*(-1))
>>> ERROR: unsupported operand type(s) for *: 'float' and 'generator'
我想知道我的约束代码是否正确(变量类型的选择等),以及如何修复拆分 objective。我很感激任何帮助,因为我已经尝试了不同的变量,但就是不行 运行.
对于#1,您的约束公式看起来是正确的。您可以通过使用 m.open_folder() 打开 运行 文件夹并使用文本编辑器打开 .apm 文件来检查 Gekko 写的内容。它列出了所有方程式、参数、变量和 objective 语句。
对于#2,除了您包含的内容外,您可能还有其他错误。此外,参数值是固定的 - objective 函数通常具有由优化器调整的变量类型。否则,如果 objective 函数仅包含参数值,那么它是一个不会影响解决方案的常数,除非从 objective.
中添加或减去一个常数下面是一个简单的程序,您可以使用它来研究 Gekko 如何编写模型 .apm 文件。
from gekko import GEKKO
import pandas as pd
m = GEKKO()
print(m._path)
x = m.Array(m.Var,(3,4))
mydict = [{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000 }]
w = pd.DataFrame(mydict)
y = [0,2]
z = [1,3]
for p in range(len(y)):
m.Equation(sum(x[p][e] for e in range(len(z)))==1)
for p in range(len(y)):
for e in range(len(z)):
m.Equation(x[p][e] < w.iloc[e][p])
for p in range(np.size(x,0)):
for e in range(np.size(x,1)):
m.Obj(x[p][e]**2)
m.solve(disp=True)
print(x)
m.open_folder()