MIPS 程序卡在嵌套函数上
MIPS program gets stuck on nested function
在 Ch 的 jal 指令之后,我的程序似乎卡在了 box_1。我认为这与 $ra 被覆盖有关。我该如何解决这个问题?
该程序应该是一个简单的比特币矿工。这是图表:
我正在使用 this 文章。
我认为解决这个问题的方法可能与在堆栈上保存 $ra 有关,但这似乎有点不切实际且效率低下?可能我做错了什么。
.data
A: .word 0x87564C0C
B: .word 0xF1369725
C: .word 0x82E6D493
D: .word 0x63A6B509
E: .word 0xDD9EFF54
F: .word 0xE07C2655
G: .word 0xA41F32E7
H: .word 0xC7D25631
W: .word 0x6534EA14
K: .word 0xC67178F2
.text
.globl main
main:
li $s0,0 #loop counter
li $s1,64 #loop limit
main_loop:
bge $s0,$s1,end_main_loop
jal box_0
move $a0,$v0 #save return value in $a0 to be used as argument by box_1
jal box_1
move $a0,$v0 #
jal box_2
move $a0,$v0 #
move $s2,$a0 #will be necessary for the input of box_4 later
jal box_3
move $s3,$v0 #Will be assigned to E later
jal box_4
move $a0,$v0 #
jal box_5
###Assignments
lw $a0,G
la $a1,H
sw $a0,($a1) #Old G goes into new H
lw $a0,F
la $a1,G
sw $a0,($a1) #Old F goes into new G
lw $a0,E
la $a1,F
sw $a0,($a1) #Old E goes into new F
#
la $a1,E
sw $s3,($a1) #Output of box_3 goes into new E
#
lw $a0,C
la $a1,D
sw $a0,($a1) #Old C goes into new D
lw $a0,B
la $a1,C
sw $a0,($a1) #Old B goes into new C
lw $a0,A
la $a1,B
sw $a0,($a1) #Old A goes into new B
#
la $a0,A
sw $v0,($a0) #Output of box_5 goes into new A
addi $s0,$s0,1 #increment loop counter
end_main_loop:
li $v0, 10 # terminate program
syscall
.text
.globl red_boxes
red_boxes:
box_0:
lw $t0,W
lw $t1,K
addu $t0,$t0,$t1 #Wt + Kt
move $v0,$t1
jr $ra
box_1:
move $t0,$a0 #output of box_0
jal Ch
move $t1,$v0
lw $t3,H
addu $t0,$t0,$t1
addu $t3,$t0,$t3
move $v0,$t3
jr $ra
box_2:
move $t0,$a0 #output of box_1
#move $t1,$a1 #output of Sigma1
jal Sigma1
move $t1,$v0
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
box_3:
move $t0,$a0 #output of box_2
lw $t1,D
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
box_4:
move $t0,$a0 #output of box_2 <----!!
#move $t1,$a1 #output of Ma
jal Ma
move $t1,$v0
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
box_5:
move $t0,$a0 #output of box_4
#move $t1,$a1 #output of Sigma0
jal Sigma0
move $t1,$v0
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
.text
.globl op_boxes
op_boxes:
Ch:
# (G&!E) || (F&E)
lw $t0,E
lw $t1,F
lw $t2,G
and $t1,$t1,$t0 #(F&E)
not $t0,$t0 #!E
and $t2,$t2,$t0 #(G&!E)
or $t0,$t1,$t2 #(G&!E) || (F&E)
move $v0,$t0
jr $ra
Sigma1:
lw $t0,E
ror $t1,$t0,6 #rotates E to the right by 6 bits
ror $t2,$t0,11 # ''' by 11 bits
ror $t3,$t0,25 # ''' by 25 bits
addu $t2,$t2,$t1 # A->6 + A->11
addu $t3,$t3,$t2 # (A->6 + A->11) + A->25
li $t1,1
and $t1,$t3,$t1
move $v0,$t1
jr $ra
Ma:
# majority = (A&B) | (B&C)
lw $t0,A
lw $t1,B
lw $t2,C
or $t3, $t0, $t2
and $t1, $t1, $t3
and $v0, $t0, $t2
or $v0, $t1, $v0
jr $ra
Sigma0:
#Same as Sigma0 but shifted by different values
lw $t0,A
ror $t1,$t0,2
ror $t2,$t0,13
ror $t3,$t0,22
add $t2,$t2,$t1
add $t3,$t3,$t2
li $t1,1
and $t1,$t3,$t1
move $v0,$t1
jr $ra
此外,我使用了 addu 而不是 add,因为有时我会溢出。这个对吗?这篇文章没有提到溢出。
saving $ra on the stack but that seems a bit unpractical and inefficient?
如果您确切知道什么寄存器 Ch(及其所有被调用者,此处 none),那么您可以将 $ra 保存在这些寄存器之一而不是堆栈中以保存在这里和那里循环。
如果您使用的是 RISC V,则可以在调用 Ch 时为 return 地址使用备用寄存器,然后在此处避免使用 $ra,就不需要完全保留 $ra。
如果你真的想优化代码,有几种方法:
一个是开发程序范围的寄存器分配,这样您就不必继续加载和存储那些全局变量,而只需操作寄存器即可。
(如果程序变得非常大,或者您还想混合使用编译器生成的 C 代码的调用,这可能很难做到——因为编译器不一定知道您的程序范围的寄存器分配。然而,如果你把它写成一个由 C 调用的子程序但不回调 C — 只 returns 到 C — 你仍然可以对整个子程序寄存器赋值。)
另一种方法是内联所有方法 — 快速浏览一下,调用重用似乎并不多,因此似乎表明了这种内联。
这两种方法可以结合使用。
是的,当我们不关心溢出时,addu 是合适的。它产生与 add 相同的位模式,但只是放弃了溢出检查。
在 Ch 的 jal 指令之后,我的程序似乎卡在了 box_1。我认为这与 $ra 被覆盖有关。我该如何解决这个问题?
该程序应该是一个简单的比特币矿工。这是图表:
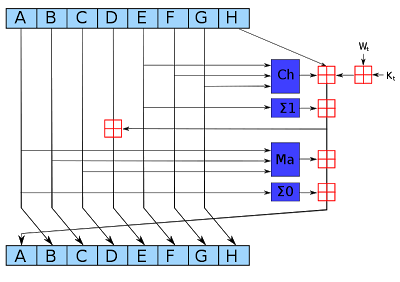{kind=link}
我正在使用 this 文章。
我认为解决这个问题的方法可能与在堆栈上保存 $ra 有关,但这似乎有点不切实际且效率低下?可能我做错了什么。
.data
A: .word 0x87564C0C
B: .word 0xF1369725
C: .word 0x82E6D493
D: .word 0x63A6B509
E: .word 0xDD9EFF54
F: .word 0xE07C2655
G: .word 0xA41F32E7
H: .word 0xC7D25631
W: .word 0x6534EA14
K: .word 0xC67178F2
.text
.globl main
main:
li $s0,0 #loop counter
li $s1,64 #loop limit
main_loop:
bge $s0,$s1,end_main_loop
jal box_0
move $a0,$v0 #save return value in $a0 to be used as argument by box_1
jal box_1
move $a0,$v0 #
jal box_2
move $a0,$v0 #
move $s2,$a0 #will be necessary for the input of box_4 later
jal box_3
move $s3,$v0 #Will be assigned to E later
jal box_4
move $a0,$v0 #
jal box_5
###Assignments
lw $a0,G
la $a1,H
sw $a0,($a1) #Old G goes into new H
lw $a0,F
la $a1,G
sw $a0,($a1) #Old F goes into new G
lw $a0,E
la $a1,F
sw $a0,($a1) #Old E goes into new F
#
la $a1,E
sw $s3,($a1) #Output of box_3 goes into new E
#
lw $a0,C
la $a1,D
sw $a0,($a1) #Old C goes into new D
lw $a0,B
la $a1,C
sw $a0,($a1) #Old B goes into new C
lw $a0,A
la $a1,B
sw $a0,($a1) #Old A goes into new B
#
la $a0,A
sw $v0,($a0) #Output of box_5 goes into new A
addi $s0,$s0,1 #increment loop counter
end_main_loop:
li $v0, 10 # terminate program
syscall
.text
.globl red_boxes
red_boxes:
box_0:
lw $t0,W
lw $t1,K
addu $t0,$t0,$t1 #Wt + Kt
move $v0,$t1
jr $ra
box_1:
move $t0,$a0 #output of box_0
jal Ch
move $t1,$v0
lw $t3,H
addu $t0,$t0,$t1
addu $t3,$t0,$t3
move $v0,$t3
jr $ra
box_2:
move $t0,$a0 #output of box_1
#move $t1,$a1 #output of Sigma1
jal Sigma1
move $t1,$v0
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
box_3:
move $t0,$a0 #output of box_2
lw $t1,D
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
box_4:
move $t0,$a0 #output of box_2 <----!!
#move $t1,$a1 #output of Ma
jal Ma
move $t1,$v0
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
box_5:
move $t0,$a0 #output of box_4
#move $t1,$a1 #output of Sigma0
jal Sigma0
move $t1,$v0
addu $t0,$t0,$t1
move $v0,$t0
jr $ra
.text
.globl op_boxes
op_boxes:
Ch:
# (G&!E) || (F&E)
lw $t0,E
lw $t1,F
lw $t2,G
and $t1,$t1,$t0 #(F&E)
not $t0,$t0 #!E
and $t2,$t2,$t0 #(G&!E)
or $t0,$t1,$t2 #(G&!E) || (F&E)
move $v0,$t0
jr $ra
Sigma1:
lw $t0,E
ror $t1,$t0,6 #rotates E to the right by 6 bits
ror $t2,$t0,11 # ''' by 11 bits
ror $t3,$t0,25 # ''' by 25 bits
addu $t2,$t2,$t1 # A->6 + A->11
addu $t3,$t3,$t2 # (A->6 + A->11) + A->25
li $t1,1
and $t1,$t3,$t1
move $v0,$t1
jr $ra
Ma:
# majority = (A&B) | (B&C)
lw $t0,A
lw $t1,B
lw $t2,C
or $t3, $t0, $t2
and $t1, $t1, $t3
and $v0, $t0, $t2
or $v0, $t1, $v0
jr $ra
Sigma0:
#Same as Sigma0 but shifted by different values
lw $t0,A
ror $t1,$t0,2
ror $t2,$t0,13
ror $t3,$t0,22
add $t2,$t2,$t1
add $t3,$t3,$t2
li $t1,1
and $t1,$t3,$t1
move $v0,$t1
jr $ra
此外,我使用了 addu 而不是 add,因为有时我会溢出。这个对吗?这篇文章没有提到溢出。
saving $ra on the stack but that seems a bit unpractical and inefficient?
如果您确切知道什么寄存器 Ch(及其所有被调用者,此处 none),那么您可以将 $ra 保存在这些寄存器之一而不是堆栈中以保存在这里和那里循环。
如果您使用的是 RISC V,则可以在调用 Ch 时为 return 地址使用备用寄存器,然后在此处避免使用 $ra,就不需要完全保留 $ra。
如果你真的想优化代码,有几种方法:
一个是开发程序范围的寄存器分配,这样您就不必继续加载和存储那些全局变量,而只需操作寄存器即可。
(如果程序变得非常大,或者您还想混合使用编译器生成的 C 代码的调用,这可能很难做到——因为编译器不一定知道您的程序范围的寄存器分配。然而,如果你把它写成一个由 C 调用的子程序但不回调 C — 只 returns 到 C — 你仍然可以对整个子程序寄存器赋值。)
另一种方法是内联所有方法 — 快速浏览一下,调用重用似乎并不多,因此似乎表明了这种内联。
这两种方法可以结合使用。
是的,当我们不关心溢出时,addu 是合适的。它产生与 add 相同的位模式,但只是放弃了溢出检查。