对 cpu 缓存基准测试结果感到困惑
Confused about cpu cache benchmark results
Ulrich Drepper 的“What Every Programmer Should Know About Memory”的 Section 3.3.2 描述了一个简单的基准测试,演示了缓存对顺序读取的影响。基准测试包括遵循一个(顺序排列的)循环链表并测量每个节点花费的平均时间。节点结构如下所示:
struct l {
struct l *n;
long int pad[NPAD];
};
大小为 N 的工作集包含 N/sizeof(l) 个节点。有了足够的填充,每个指针都存储在不同的缓存行中,所以我们需要一个至少 64 * N/sizeof(l) 大小的缓存来跟随循环而不需要昂贵的内存访问。
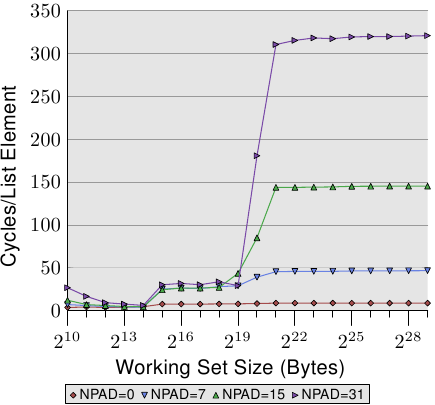
这是让我感到困惑的部分:假设 64 * N/sizeof(l) 恰好是最大缓存的大小。例如,如果我们通过更改填充将 sizeof(l) 减半,如果我们希望所有内容仍适合缓存,N 也需要小 2 倍。因此,随着不同的步幅,我们应该 运行 在不同的工作集大小下从缓存中取出。但是文本中的 Figure 3.11(我没有足够的代表来嵌入图像)似乎与此相矛盾 - 对于所有三种 NPAD 大小,访问时间的突然跳跃都发生在 N=2^19。
我错过了什么?
起初我以为填充也可能被缓存了 - 但正如 this question.
的答案中所解释的那样,事实并非如此
With enough padding, each pointer is stored in different cache line, so we need a cache of size at least 64 * N/sizeof(l) to follow the cycle without expensive memory access.
不是,如果一个cache line是64字节,如果sizeof(struct l)至少是64,那么每个节点在不同的cache line中。但这不是3.3.2节的重点。
Assume that 64 * N/sizeof(l) is exactly the size of the biggest cache. If we, say, halve sizeof(l) by changing the padding, N also needs to be 2x smaller if we want everything to still fit in the cache.
缓存的大小是固定的字节数,而不是64 * N/sizeof(l)这样的计算。在您引用的本小节部分,Drepper 使用 1 MiB(220 字节)L2 缓存。此外,Drepper 使用 N 来描述“工作集大小”(显然是总数组大小,尽管在某些试验中并非所有数组都被访问)为 2N 字节,因此“如果 2N 字节小于或等于缓存大小,工作集”适合缓存。如果数组大小为 2N 字节,则元素个数必须为 2N / sizeof(struct l).
在图3.11中,您看到的是:
- 只要总数组大小小于 219 字节,其中的所有内容都适合二级缓存,并且访问“很快”。
- 在 219 和 220 字节处,整个数组本身就适合缓存,但还有其他内容系统也需要缓存,所以我们看到中间效果,这里不详细讨论。
- 超过 220 字节,数组元素在连续访问时不能保留在缓存中(即使使用大填充,actually-accessed 字节总计很多小于缓存大小,缓存关联性使得它们溢出其指定的缓存集,实际上与溢出所有缓存相同)。
- 对于零填充,预取效果很好:硬件观察到内存正在被连续读取并预取缓存行。观察到,使用零填充,多个元素适合一个缓存行,因此一个缓存行的每次预取都会提供多个元素,因此每个元素的时间很短。
- 对于小填充,大概每个缓存行有一个元素,预取以相同的方式运行:硬件观察内存被连续读取并预取缓存行。但是,每个缓存行只有一个数组元素,因此每个元素的时间更长,即使每个缓存行的时间相同。
- 对于中等填充和较大填充,预取要么不运行,要么服务不佳。
我对 Drepper 的一些说法持怀疑态度。例如,关于 15 和 31 的填充之间的差异 long int(显然将元素大小从 128 字节更改为 256 字节),他写道:
Where the element size is hampering the prefetching efforts is a result of a limitation of hardware prefetching: it cannot cross page boundaries.
但是,对于 4096 字节的页面大小(根据其他地方提到的 60 页为 245,760 字节推断)和 128 到 256 字节的元素间距,读取将分别每隔 32 和 16 个元素遇到页面边界。每个元素从大约 145 个周期跳到大约 320 个周期,因为每个元素有额外的 1/32 页面转换(每 16 个元素 1 个减去每 32 个元素 1 个 = 每个元素 1/32)意味着 1/32•C = 320− 145,其中 C 是页面转换成本的周期数。那么C = (320-145)•32 = 5,600。如果没有更有针对性的测试或支持文档,我不会相信这个大数字。
Drepper 还用带括号的斜体字写道:
Yes, this is a bit inconsistent because in the other tests we count the unused part of the struct in the element size and we could define NPAD so that each element fills a page. In that case the working set sizes would be very different. This is not the point of this test, though, and since prefetching is ineffective anyway this makes little difference.
这与他之前对工作集的描述不符,他说一个 2N 字节的工作集包含 2N /sizeof(struct l) 个元素。后者显示他的“工作集”是整个数组,即使只访问了每个元素的一部分。前者说工作集会根据每个元素的访问量而变化。
总的来说,我认为 Drepper 对原因的描述和归因有些松散。尤其是在没有示例代码的情况下,很难遵循某些测试描述或重现它们。这种假设的各种大小数组元素的建模实际上是一种跳过内存只访问部分的建模——如果这些是程序正在使用的实际数组元素,它将加载整个元素,并且预取将很好地处理每个字节。一旦理解了这个令人困惑的描述,这并不会使 Drepper 的测量无效,但这是一个误导性的描述。同样,不同地方对“working set”的不同描述也让人迷惑。
所以我的建议是对这里写的东西持保留态度,不要指望它是一个完全可靠和清晰的缓存和内存性能规范。
Section 3.3.2 描述了一个简单的基准测试,演示了缓存对顺序读取的影响。基准测试包括遵循一个(顺序排列的)循环链表并测量每个节点花费的平均时间。节点结构如下所示:
struct l {
struct l *n;
long int pad[NPAD];
};
大小为 N 的工作集包含 N/sizeof(l) 个节点。有了足够的填充,每个指针都存储在不同的缓存行中,所以我们需要一个至少 64 * N/sizeof(l) 大小的缓存来跟随循环而不需要昂贵的内存访问。
这是让我感到困惑的部分:假设 64 * N/sizeof(l) 恰好是最大缓存的大小。例如,如果我们通过更改填充将 sizeof(l) 减半,如果我们希望所有内容仍适合缓存,N 也需要小 2 倍。因此,随着不同的步幅,我们应该 运行 在不同的工作集大小下从缓存中取出。但是文本中的 Figure 3.11(我没有足够的代表来嵌入图像)似乎与此相矛盾 - 对于所有三种 NPAD 大小,访问时间的突然跳跃都发生在 N=2^19。
{kind=link}
我错过了什么?
起初我以为填充也可能被缓存了 - 但正如 this question.
的答案中所解释的那样,事实并非如此With enough padding, each pointer is stored in different cache line, so we need a cache of size at least
64 * N/sizeof(l)to follow the cycle without expensive memory access.
不是,如果一个cache line是64字节,如果sizeof(struct l)至少是64,那么每个节点在不同的cache line中。但这不是3.3.2节的重点。
Assume that
64 * N/sizeof(l)is exactly the size of the biggest cache. If we, say, halvesizeof(l)by changing the padding, N also needs to be 2x smaller if we want everything to still fit in the cache.
缓存的大小是固定的字节数,而不是64 * N/sizeof(l)这样的计算。在您引用的本小节部分,Drepper 使用 1 MiB(220 字节)L2 缓存。此外,Drepper 使用 N 来描述“工作集大小”(显然是总数组大小,尽管在某些试验中并非所有数组都被访问)为 2N 字节,因此“如果 2N 字节小于或等于缓存大小,工作集”适合缓存。如果数组大小为 2N 字节,则元素个数必须为 2N / sizeof(struct l).
在图3.11中,您看到的是:
- 只要总数组大小小于 219 字节,其中的所有内容都适合二级缓存,并且访问“很快”。
- 在 219 和 220 字节处,整个数组本身就适合缓存,但还有其他内容系统也需要缓存,所以我们看到中间效果,这里不详细讨论。
- 超过 220 字节,数组元素在连续访问时不能保留在缓存中(即使使用大填充,actually-accessed 字节总计很多小于缓存大小,缓存关联性使得它们溢出其指定的缓存集,实际上与溢出所有缓存相同)。
- 对于零填充,预取效果很好:硬件观察到内存正在被连续读取并预取缓存行。观察到,使用零填充,多个元素适合一个缓存行,因此一个缓存行的每次预取都会提供多个元素,因此每个元素的时间很短。
- 对于小填充,大概每个缓存行有一个元素,预取以相同的方式运行:硬件观察内存被连续读取并预取缓存行。但是,每个缓存行只有一个数组元素,因此每个元素的时间更长,即使每个缓存行的时间相同。
- 对于中等填充和较大填充,预取要么不运行,要么服务不佳。
我对 Drepper 的一些说法持怀疑态度。例如,关于 15 和 31 的填充之间的差异 long int(显然将元素大小从 128 字节更改为 256 字节),他写道:
Where the element size is hampering the prefetching efforts is a result of a limitation of hardware prefetching: it cannot cross page boundaries.
但是,对于 4096 字节的页面大小(根据其他地方提到的 60 页为 245,760 字节推断)和 128 到 256 字节的元素间距,读取将分别每隔 32 和 16 个元素遇到页面边界。每个元素从大约 145 个周期跳到大约 320 个周期,因为每个元素有额外的 1/32 页面转换(每 16 个元素 1 个减去每 32 个元素 1 个 = 每个元素 1/32)意味着 1/32•C = 320− 145,其中 C 是页面转换成本的周期数。那么C = (320-145)•32 = 5,600。如果没有更有针对性的测试或支持文档,我不会相信这个大数字。
Drepper 还用带括号的斜体字写道:
Yes, this is a bit inconsistent because in the other tests we count the unused part of the struct in the element size and we could define NPAD so that each element fills a page. In that case the working set sizes would be very different. This is not the point of this test, though, and since prefetching is ineffective anyway this makes little difference.
这与他之前对工作集的描述不符,他说一个 2N 字节的工作集包含 2N /sizeof(struct l) 个元素。后者显示他的“工作集”是整个数组,即使只访问了每个元素的一部分。前者说工作集会根据每个元素的访问量而变化。
总的来说,我认为 Drepper 对原因的描述和归因有些松散。尤其是在没有示例代码的情况下,很难遵循某些测试描述或重现它们。这种假设的各种大小数组元素的建模实际上是一种跳过内存只访问部分的建模——如果这些是程序正在使用的实际数组元素,它将加载整个元素,并且预取将很好地处理每个字节。一旦理解了这个令人困惑的描述,这并不会使 Drepper 的测量无效,但这是一个误导性的描述。同样,不同地方对“working set”的不同描述也让人迷惑。
所以我的建议是对这里写的东西持保留态度,不要指望它是一个完全可靠和清晰的缓存和内存性能规范。