在 Julia 中导出为 CSV 文件
Exporting to CSV files in Julia
警告:这些都是菜鸟问题,因为我真的 Julia 新手。
在 R 中,有一个非常“统一”的函数可以导出(几乎)任何类型的对象 read.table()。看起来 Julia 中的事情稍微复杂一些。如果我理解的很好:
某些标准类型(例如,数组、字典和元组)始终可以使用 writedlm 导出,但并非总是可以使用 CSV.write 导出。相反,DataFrames 总是可以用 CSV.write 导出,但不能用 writedlm 导出。这个对吗?因此,与 R 的 write.table()?
类似,不存在“通用出口商”
除了写入 CSV 文件外,CSV.write 似乎还 return 导出文件的名称。相反,writedlm 则不会。这对我来说是个问题。实际上,我需要一种将 DataFrame 导出到 CSV 文件的方法,该文件具有 not return 值的功能,即仅具有副作用的功能,例如 writedlm。有什么办法可以在 Julia 中实现这一点?
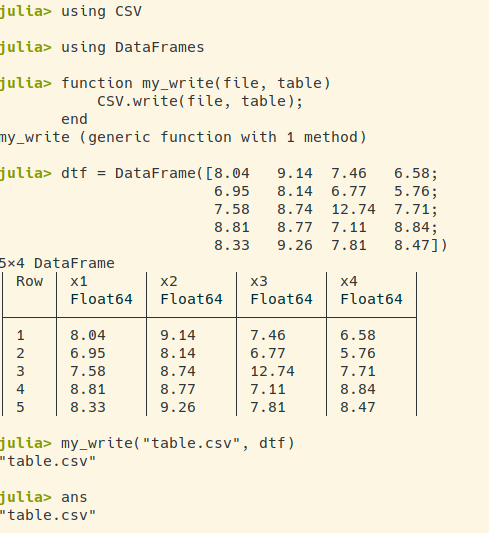
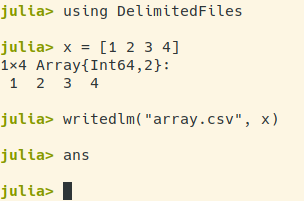
编辑:更详细地说,我的问题是在 CSV.write 之后,ans 指向导出文件的名称; writedlm 不是这种情况。插图 here and here。即使有@Przemyslaw Szufel 给出的想法,我也无法摆脱它。 (这是一个相当微妙的问题,但我实际上正在尝试为 Julia 编写一个 emacs lisp 后端。这种不一致,例如不知道 ans 是否会是 nothing 或导出后的文件名对象,在这次冒险中增加了一些痛苦......:-)理想情况下,我只是希望 CSV.write 可以保持沉默。)
谢谢!
我从第二个问题开始,因为它很短。只需在行尾使用分号 ; 并且不会返回任何值!
CSV.write(file, table);
但是,如果您想确保 ans 没有值,请在末尾添加 nothing:
CSV.write(file, table);nothing;
如果你愿意,你可以把它打包成一个函数:
function my_write(file, table)
CSV.write(file, table)
nothing
end
或者,如果您想要 one-liner 将其包装到 lambda 中:
julia> (() -> begin;CSV.write("file.csv", df);nothing;end)()
julia> ans == nothing
true
在每种情况下都不会观察到副作用(返回值)。
第一个问题比较棘手。用于在文件中存储数据的可能格式显然需要取决于数据的格式。基本上,Julia 最常见的选项包括(我从最通用的选项开始,到最具体的选项结束):
- 通过
serialize命令序列化
- 二进制 JSON 通过
BSON.jl 包
- JSON 通过
JSON.jl 或稍新的 JSON3.jl 包(从今天开始都是不错的选择)
JSONTables.jl 对于存储为 JSONDelimitedFiles用于存储ArraysCSV.jl用于存储DataFrames
现在,特定包的选择将取决于您的 objective。序列化是杀手级机制——速度最快,用途最广。任何对象都可以在尽可能短的时间内以这种方式存储。一切都是有代价的——当你更新 Julia 版本或你的包时,你可能无法读回你的对象。所以它是为短期存储而设计的。
桩子中间是 JSON-based 存储系统。基本上,所有内容都可以存储为 JSON,以后可以在 Julia 或其他编程语言中读取。基于文本的 JSON 也可以在简单的文本编辑器中打开。
最后,CSV.jl和Serialization可以分别用于表格和数组。但是,很容易将 DataFrame 转换为 Array 或将 Array 转换为 DataFrame:
julia> df = DataFrame(a=1:3, b=rand(3),c=["a","b","c"])
3×3 DataFrame
│ Row │ a │ b │ c │
│ │ Int64 │ Float64 │ String │
├─────┼───────┼──────────┼────────┤
│ 1 │ 1 │ 0.440796 │ a │
│ 2 │ 2 │ 0.44232 │ b │
│ 3 │ 3 │ 0.282064 │ c │
julia> Matrix(df)
3×3 Array{Any,2}:
1 0.440796 "a"
2 0.44232 "b"
3 0.282064 "c"
您可以看到,在此过程中唯一丢失的是类型信息,如果您通过 DelimitedFiles.
导出数据,这并不重要。
反过来的转换也很简单:
julia> rand(3,3) |> Tables.table |> DataFrame
3×3 DataFrame
│ Row │ Column1 │ Column2 │ Column3 │
│ │ Float64 │ Float64 │ Float64 │
├─────┼──────────┼───────────┼──────────┤
│ 1 │ 0.326649 │ 0.0278134 │ 0.111221 │
│ 2 │ 0.769378 │ 0.996156 │ 0.237821 │
│ 3 │ 0.802094 │ 0.726497 │ 0.619013 │
总之,如您所见,一切都可以在 Julia 中完成。
警告:这些都是菜鸟问题,因为我真的 Julia 新手。
在 R 中,有一个非常“统一”的函数可以导出(几乎)任何类型的对象 read.table()。看起来 Julia 中的事情稍微复杂一些。如果我理解的很好:
某些标准类型(例如,数组、字典和元组)始终可以使用
类似,不存在“通用出口商”writedlm导出,但并非总是可以使用CSV.write导出。相反,DataFrames 总是可以用CSV.write导出,但不能用writedlm导出。这个对吗?因此,与 R 的write.table()?除了写入 CSV 文件外,
CSV.write似乎还 return 导出文件的名称。相反,writedlm则不会。这对我来说是个问题。实际上,我需要一种将 DataFrame 导出到 CSV 文件的方法,该文件具有 not return 值的功能,即仅具有副作用的功能,例如writedlm。有什么办法可以在 Julia 中实现这一点?编辑:更详细地说,我的问题是在
CSV.write之后,ans指向导出文件的名称;writedlm不是这种情况。插图 here and here。即使有@Przemyslaw Szufel 给出的想法,我也无法摆脱它。 (这是一个相当微妙的问题,但我实际上正在尝试为 Julia 编写一个 emacs lisp 后端。这种不一致,例如不知道ans是否会是nothing或导出后的文件名对象,在这次冒险中增加了一些痛苦......:-)理想情况下,我只是希望CSV.write可以保持沉默。)
{kind=link}
{kind=link}
谢谢!
我从第二个问题开始,因为它很短。只需在行尾使用分号 ; 并且不会返回任何值!
CSV.write(file, table);
但是,如果您想确保 ans 没有值,请在末尾添加 nothing:
CSV.write(file, table);nothing;
如果你愿意,你可以把它打包成一个函数:
function my_write(file, table)
CSV.write(file, table)
nothing
end
或者,如果您想要 one-liner 将其包装到 lambda 中:
julia> (() -> begin;CSV.write("file.csv", df);nothing;end)()
julia> ans == nothing
true
在每种情况下都不会观察到副作用(返回值)。
第一个问题比较棘手。用于在文件中存储数据的可能格式显然需要取决于数据的格式。基本上,Julia 最常见的选项包括(我从最通用的选项开始,到最具体的选项结束):
- 通过
serialize命令序列化 - 二进制 JSON 通过
BSON.jl包 - JSON 通过
JSON.jl或稍新的JSON3.jl包(从今天开始都是不错的选择) JSONTables.jl对于存储为 JSON 的表格数据
DelimitedFiles用于存储ArraysCSV.jl用于存储DataFrames
现在,特定包的选择将取决于您的 objective。序列化是杀手级机制——速度最快,用途最广。任何对象都可以在尽可能短的时间内以这种方式存储。一切都是有代价的——当你更新 Julia 版本或你的包时,你可能无法读回你的对象。所以它是为短期存储而设计的。
桩子中间是 JSON-based 存储系统。基本上,所有内容都可以存储为 JSON,以后可以在 Julia 或其他编程语言中读取。基于文本的 JSON 也可以在简单的文本编辑器中打开。
最后,CSV.jl和Serialization可以分别用于表格和数组。但是,很容易将 DataFrame 转换为 Array 或将 Array 转换为 DataFrame:
julia> df = DataFrame(a=1:3, b=rand(3),c=["a","b","c"])
3×3 DataFrame
│ Row │ a │ b │ c │
│ │ Int64 │ Float64 │ String │
├─────┼───────┼──────────┼────────┤
│ 1 │ 1 │ 0.440796 │ a │
│ 2 │ 2 │ 0.44232 │ b │
│ 3 │ 3 │ 0.282064 │ c │
julia> Matrix(df)
3×3 Array{Any,2}:
1 0.440796 "a"
2 0.44232 "b"
3 0.282064 "c"
您可以看到,在此过程中唯一丢失的是类型信息,如果您通过 DelimitedFiles.
反过来的转换也很简单:
julia> rand(3,3) |> Tables.table |> DataFrame
3×3 DataFrame
│ Row │ Column1 │ Column2 │ Column3 │
│ │ Float64 │ Float64 │ Float64 │
├─────┼──────────┼───────────┼──────────┤
│ 1 │ 0.326649 │ 0.0278134 │ 0.111221 │
│ 2 │ 0.769378 │ 0.996156 │ 0.237821 │
│ 3 │ 0.802094 │ 0.726497 │ 0.619013 │
总之,如您所见,一切都可以在 Julia 中完成。