如何在 Hadoop/HDP 组件中配置日志记录?
How to configure logging in Hadoop / HDP components?
我有一个 HDP 2.4 集群,其中 services/components:
- HBase
- 卡夫卡
- MapReduce2
- 风暴
- 奥齐
- 支持 Zookeeper、Ambari、Yarn、HDFS 等服务
我已经搜索了好几天了,希望能得到一些帮助。我有以下两个问题:
- 如何在应用程序级别(我们使用 log4j)和守护程序级别为下面提到的所有服务配置日志记录?
- 在一个统一位置查看这些服务的所有应用程序级日志的最佳做法是什么? Ambari 是否可以提供一些东西或者我们是否需要第三方包(哪些是好的)?
非常感谢您提供的任何帮助!
如果您正在编写利用一个或多个 HDP 服务的应用程序,我建议为每个服务更新 log4j.properties 文件以匹配您需要的日志记录级别。最好的方法是使用 Ambari Admin UI。要编辑服务的 log4j.properties,请按照以下步骤操作:
- Click any one of the services on the left-hand side of the Dashboard.
- Once the Service Summary page has loaded, click the 'Configs' tab at the top of the screen.
- Click the 'Advanced' tab underneath the Version History Timeline, find the 'Advanced' set of properties and then search for the log4j.properties entry. Failing that, you can search for 'log4j' in the search bar at the top-right of the screen and Ambari will highlight the relevant settings.
有关 HDFS 服务的 log4j.properties 文件示例的详细图像,请参阅 here。
请记住,每个服务的日志文件只会捕获您的应用程序与该服务之间的交互 仅。如果您在 Java 工作,我个人建议在您的应用程序中添加一个 log4j 实例;如果您不知道如何操作,我的建议是按照 this tutorial (found on this SO question) 进行正确设置。根据您的应用程序调用每个服务的 API 的方式,您可以查询命令的输出并将其记录到您自己的日志文件中。
就在一个集中位置查看日志文件而言,您有两种选择:
- 升级到 HDP 2.5 以使用 Ambari 日志搜索。
- 继续使用 HDP 2.4 并使用 Flume.
从头开始创建解决方案
我将在下面概述两个选项。
1。升级到 HDP 2.5 以使用 Ambari 日志搜索。
我认为 "easier" 方法(我的意思是需要您付出最少的努力)会将您的集群升级到 HDP 2.5。更新后的 Hortonworks 数据平台通过其最新版本 Ambari 2.4 对 Ambari 进行了重大改革。此版本包括 Ambari Infra,它允许您查看所有日志文件、按日志级别过滤并执行图形和复杂功能,这要归功于 Ambari Log Search。
如果升级整个集群不可行,另一种选择是从 Hortonworks 的网站获取 Ambari 2.4 存储库并手动安装。 Hortonworks 的一位代表建议我,Ambari 2.4 可以 运行 在 HDP 2.4 上毫无问题,所以这可能是一个可行的替代方案......尽管我建议您在尝试之前先与 Hortonworks 核实一下!
Ambari 日志搜索的唯一缺点是您无法在搜索中包含您的应用程序日志 - Ambari 日志搜索仅适用于 Hadoop 服务。
2。继续使用 HDP 2.4 并使用 Flume.
从头开始创建解决方案
如果你不想升级到Ambari 2.4,那么其他的选项看起来有点匮乏。我个人并不知道任何开源解决方案,并且粗略地谷歌搜索 returns 一些结果。 Apache Chukwa and Cloudera's Scribe both are supposed to address distributed log collection in Hadoop but are both 9 years old. There's also an older Hortonworks process for log collection that leverages Flume for the same process which might be worth a look at. This SO thread 还建议 Flume 用于其他情况。可能值得考虑使用 Flume.
从每个服务器 /var/log/ 目录收集日志
此解决方案的优点是您的应用程序日志文件可以作为源包含在 Flume 工作流中,并与其他 HDP 服务日志一起包含(取决于您决定放置它们的位置)。
如果您使用 HDP,您应该查看这篇文章(显示如何配置 log4j):
How to control size of log files for various HDP components?
这个也很有用(展示了如何使用 log4j 压缩 HDFS 日志):
How to rotate as well as zip the NameNode logs using log4j extras feature?
我有一个 HDP 2.4 集群,其中 services/components:
- HBase
- 卡夫卡
- MapReduce2
- 风暴
- 奥齐
- 支持 Zookeeper、Ambari、Yarn、HDFS 等服务
我已经搜索了好几天了,希望能得到一些帮助。我有以下两个问题:
- 如何在应用程序级别(我们使用 log4j)和守护程序级别为下面提到的所有服务配置日志记录?
- 在一个统一位置查看这些服务的所有应用程序级日志的最佳做法是什么? Ambari 是否可以提供一些东西或者我们是否需要第三方包(哪些是好的)?
非常感谢您提供的任何帮助!
如果您正在编写利用一个或多个 HDP 服务的应用程序,我建议为每个服务更新 log4j.properties 文件以匹配您需要的日志记录级别。最好的方法是使用 Ambari Admin UI。要编辑服务的 log4j.properties,请按照以下步骤操作:
- Click any one of the services on the left-hand side of the Dashboard.
- Once the Service Summary page has loaded, click the 'Configs' tab at the top of the screen.
- Click the 'Advanced' tab underneath the Version History Timeline, find the 'Advanced' set of properties and then search for the log4j.properties entry. Failing that, you can search for 'log4j' in the search bar at the top-right of the screen and Ambari will highlight the relevant settings.
有关 HDFS 服务的 log4j.properties 文件示例的详细图像,请参阅 here。
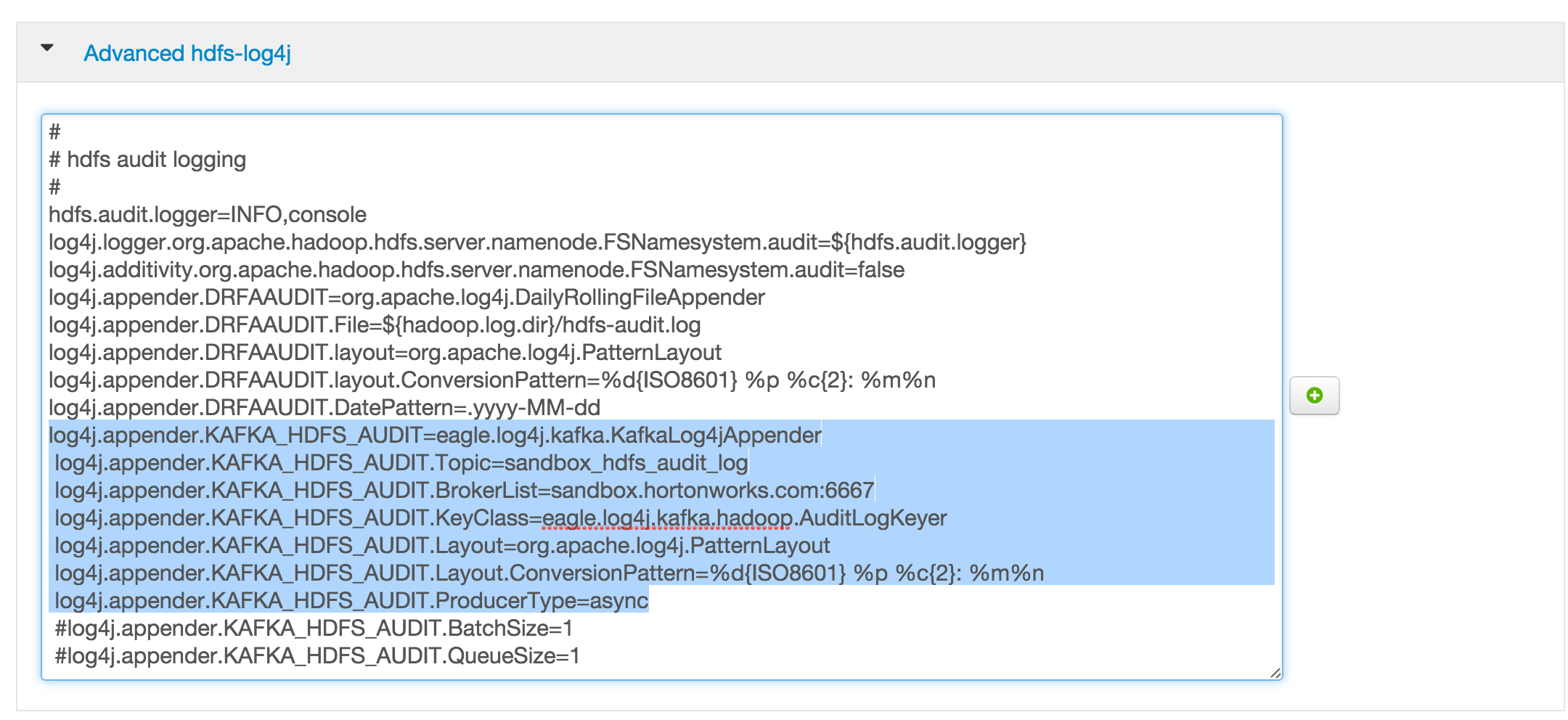{kind=link}
请记住,每个服务的日志文件只会捕获您的应用程序与该服务之间的交互 仅。如果您在 Java 工作,我个人建议在您的应用程序中添加一个 log4j 实例;如果您不知道如何操作,我的建议是按照 this tutorial (found on this SO question) 进行正确设置。根据您的应用程序调用每个服务的 API 的方式,您可以查询命令的输出并将其记录到您自己的日志文件中。
就在一个集中位置查看日志文件而言,您有两种选择:
- 升级到 HDP 2.5 以使用 Ambari 日志搜索。
- 继续使用 HDP 2.4 并使用 Flume. 从头开始创建解决方案
我将在下面概述两个选项。
1。升级到 HDP 2.5 以使用 Ambari 日志搜索。
我认为 "easier" 方法(我的意思是需要您付出最少的努力)会将您的集群升级到 HDP 2.5。更新后的 Hortonworks 数据平台通过其最新版本 Ambari 2.4 对 Ambari 进行了重大改革。此版本包括 Ambari Infra,它允许您查看所有日志文件、按日志级别过滤并执行图形和复杂功能,这要归功于 Ambari Log Search。
如果升级整个集群不可行,另一种选择是从 Hortonworks 的网站获取 Ambari 2.4 存储库并手动安装。 Hortonworks 的一位代表建议我,Ambari 2.4 可以 运行 在 HDP 2.4 上毫无问题,所以这可能是一个可行的替代方案......尽管我建议您在尝试之前先与 Hortonworks 核实一下!
Ambari 日志搜索的唯一缺点是您无法在搜索中包含您的应用程序日志 - Ambari 日志搜索仅适用于 Hadoop 服务。
2。继续使用 HDP 2.4 并使用 Flume.
从头开始创建解决方案如果你不想升级到Ambari 2.4,那么其他的选项看起来有点匮乏。我个人并不知道任何开源解决方案,并且粗略地谷歌搜索 returns 一些结果。 Apache Chukwa and Cloudera's Scribe both are supposed to address distributed log collection in Hadoop but are both 9 years old. There's also an older Hortonworks process for log collection that leverages Flume for the same process which might be worth a look at. This SO thread 还建议 Flume 用于其他情况。可能值得考虑使用 Flume.
从每个服务器/var/log/ 目录收集日志
此解决方案的优点是您的应用程序日志文件可以作为源包含在 Flume 工作流中,并与其他 HDP 服务日志一起包含(取决于您决定放置它们的位置)。
如果您使用 HDP,您应该查看这篇文章(显示如何配置 log4j):
How to control size of log files for various HDP components?
这个也很有用(展示了如何使用 log4j 压缩 HDFS 日志):
How to rotate as well as zip the NameNode logs using log4j extras feature?